In this article, I will provide a rough overview of the main process from implementing HOTP to TOTP. I won’t delve into the detailed explanations of each line of code; instead, the primary focus will be on extracting the implementation steps and highlighting some points I encountered during the development process that require attention.
Dans cet article, je vais donner un aperçu général du processus principal de la mise en œuvre de HOTP à TOTP. Je n’entrerai pas dans les explications détaillées de chaque ligne de code ; à la place, l’accent principal sera mis sur l’extraction des étapes de mise en œuvre et la mise en évidence de certains points que j’ai rencontrés lors du processus de développement qui nécessitent une attention particulière.
To implement RFC 6238 (TOTP), it has been stated in the standard’s Abstract section that TOTP is an extension of HOTP (RFC 4226), thus requiring the implementation of RFC 4226 (HOTP).
Pour mettre en œuvre RFC 6238 (TOTP), il a été indiqué dans la section Résumé de la norme que TOTP est une extension de HOTP (RFC 4226), ce qui nécessite donc la mise en œuvre de RFC 4226 (HOTP).
This document describes an extension of the One-Time Password (OTP) algorithm, namely the HMAC-based One-Time Password (HOTP) algorithm, as defined in RFC 4226, to support the time-based moving factor.
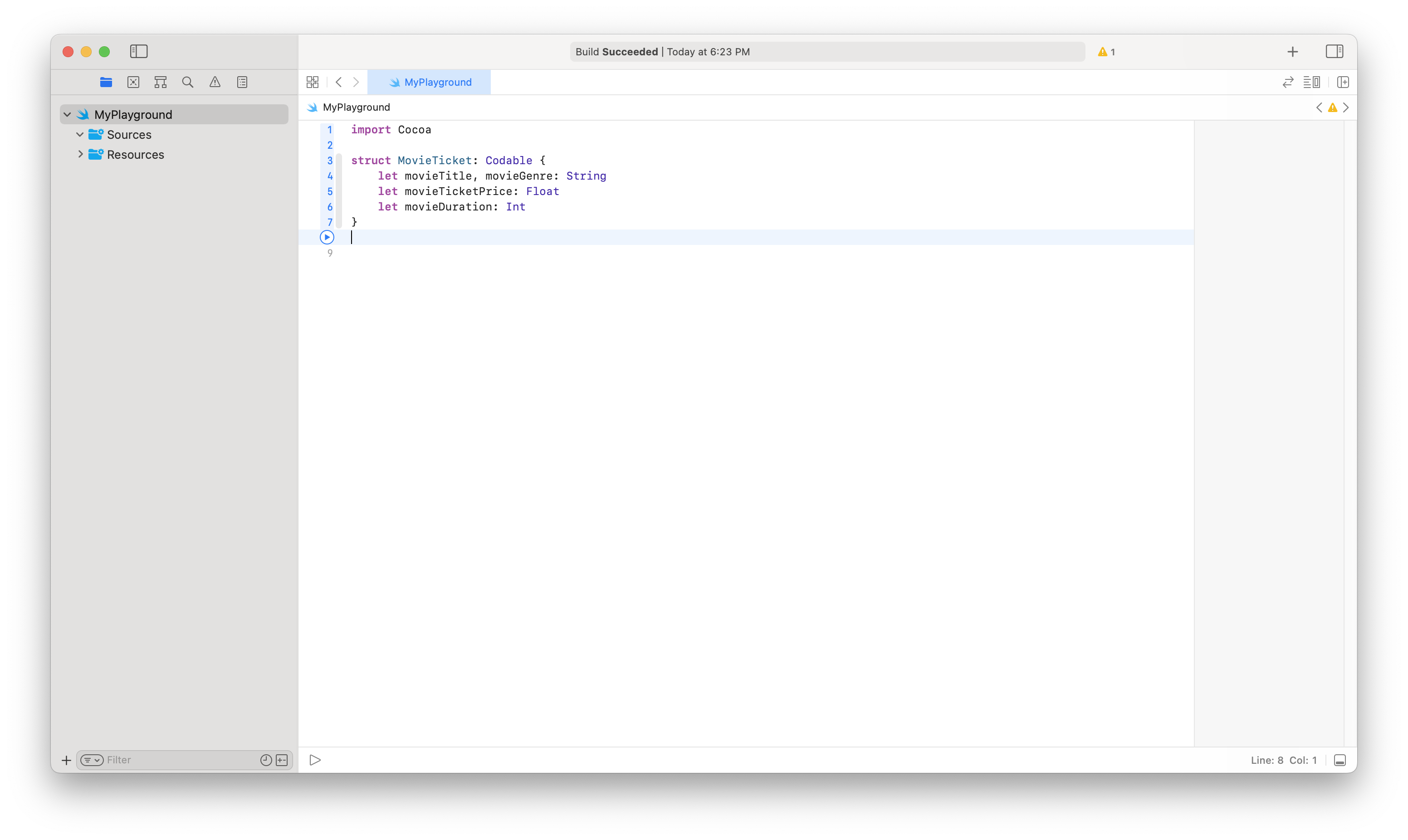
Implementing HOTP requires three essential parameters that we will be using today:
Key
Counter
Digit
La mise en œuvre de HOTP nécessite trois paramètres essentiels que nous utiliserons aujourd’hui :
Clé
Compteur
Chiffre
实现 HOTP 有三个重要的,今天我们会用到的参数
Key
Counter
Digit
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Symbol Represents ------------------------------------------------------------------- C 8-byte counter value, the moving factor. This counter MUST be synchronized between the HOTP generator (client) and the HOTP validator (server).
K shared secret between client and server; each HOTP generator has a different and unique secret K.
T throttling parameter: the server will refuse connections from a user after T unsuccessful authentication attempts.
s resynchronization parameter: the server will attempt to verify a received authenticator across s consecutive counter values.
Digit number of digits in an HOTP value; system parameter.
Step 1
Using the HMAC-SHA1 algorithm, generate the hash value hs. The key is the aforementioned K (Key), and the message is C (Counter in 8 bytes).
Utilisez l’algorithme HMAC-SHA1 pour générer la valeur de hachage hs. La clé est la K (Clé) mentionnée précédemment, et le message est C (Compteur sur 8 octets).
利用 HMAC-SHA1 算法生成出散列值 hs。密钥是上文提到的 K (Key) ,消息为 C (Counter in 8-byte)
1
Step 1: Generate an HMAC-SHA-1 value Let HS = HMAC-SHA-1(K,C) // HS is a 20-byte string
1 2
var hmac = new HMACSHA1(Secret); var hs = hmac.ComputeHash(Counter);
The code above is written in C#, keeping only the main parts as an example.
Le code ci-dessus est écrit en C#, ne conservant que les parties principales à titre d’exemple.
上面的代码使用 C# 编写,仅保留主要部分作为示例
Step 2
This step requires using a method called Dynamic Truncation to convert the 20-byte HMAC hash result into a shorter fixed code, which serves as a one-time password.
Cette étape nécessite l’utilisation d’une méthode appelée Dynamic Truncation pour convertir le résultat de hachage HMAC de 20 octets en un code fixe plus court, qui sert de mot de passe à usage unique.
privateintDynamicTruncation(byte[] p) { var offset = p.Last() & 0x0F; // Offset value
return ((p[offset] & 0x7F) << 24) | ((p[offset + 1] & 0xFF) << 16) | ((p[offset + 2] & 0xFF) << 8) | (p[offset + 3] & 0xFF); // Return the Last 31 bits of p }
This step has completed the entire second step, and the return type is an integer, as we will use it for numerical operations in the third step.
Cette étape a achevé l’ensemble de la deuxième étape, et le type de retour est un entier, car nous l’utiliserons pour des opérations numériques dans la troisième étape.
这一步已经完成了整个第二步,返回类型为整数,因为我们要带入第三步参与数字运算
Step 3
1 2 3 4 5
Step 3: Compute an HOTP value Let Snum = StToNum(Sbits) // Convert S to a number in 0...2^{31}-1 Return D = Snum mod 10^Digit // D is a number in the range 0...10^{Digit}-1
In this step, we need to perform a modulo operation on the number we obtained. The algorithm is num % 10^Digit.
Dans cette étape, nous devons effectuer une opération de modulo sur le nombre que nous avons obtenu. L’algorithme est le suivant : num % 10^Digit.
这一步需要将我们得到的数字进行取模运算,算法为 num % 10^Digit
1
var code = (DynamicTruncation(hs) % (int)Math.Pow(10, Digit)) // hs is defined in Step 1.
At this point, the one-time password generation for HOTP is complete, and we will convert it to a string type.
À ce stade, la génération du mot de passe à usage unique pour HOTP est terminée, et nous allons le convertir en type chaîne de caractères.
到这一步就完成了 HOTP 的一次性密码生成,我们将它转为字符串类型
1
var code = (DynamicTruncation(hs) % (int)Math.Pow(10, Digit)).ToString().PadLeft(Digit, '0');
Since we are working with numerical data when calculating Dynamic Truncation and performing modulo operations on numbers, if a one-time password includes a 0 in the highest order of magnitude, the mathematical 0 will be discarded. Therefore, when we convert this to a string (or any data type in any language that represents arbitrary text), we need to apply the corresponding PadLeft operation. In this case, you can use the string.PadLeft() method directly in C#.
Étant donné que nous travaillons avec des données numériques lors du calcul de la Troncature Dynamique et lors de l’exécution d’opérations de modulo sur des nombres, si un mot de passe à usage unique inclut un 0 dans la position la plus élevée, le 0 mathématique sera ignoré. Par conséquent, lorsque nous le convertissons en une chaîne de caractères (ou tout autre type de données dans n’importe quel langage qui représente du texte arbitraire), nous devons effectuer l’opération PadLeft correspondante. Dans ce cas, vous pouvez utiliser directement la méthode string.PadLeft() en C#.
publicHOTP(byte[] secret, int counter, int digit) { Secret = secret; Digit = digit; var bytes = newbyte[8];
for (var i = 7; i >= 0; i--) { bytes[i] = (byte)(counter & 0xFF);
counter >>= 8; }
Counter = bytes; }
publicstringCode() { var hmac = new HMACSHA1(Secret); var hs = hmac.ComputeHash(Counter); var code = (DynamicTruncation(hs) % (int)Math.Pow(10, Digit)).ToString().PadLeft(Digit, '0');
return code; }
privateintDynamicTruncation(byte[] p) { var offset = p.Last() & 0x0F;
C:\Users\xyfbs\source\repos\ConsoleTotp\ConsoleTotp\bin\Debug\net7.0\ConsoleTotp.exe (process 26588) exited with code 0. To automatically close the console when debugging stops, enable Tools->Options->Debugging->Automatically close the console when debugging stops. Press any key to close this window . . .
With the completion of the implementation of HOTP, we have already accomplished more than half of the entire project. Since TOTP is an extension of HOTP, our workload will be significantly reduced.
Avec l’achèvement de la mise en œuvre de HOTP, nous avons déjà accompli plus de la moitié de l’ensemble du projet. Étant donné que TOTP est une extension de HOTP, notre charge de travail sera considérablement réduite.
o X represents the time step in seconds (default value X = 30 seconds) and is a system parameter.
o T0 is the Unix time to start counting time steps (default value is 0, i.e., the Unix epoch) and is also a system parameter.
Basically, we define TOTP as TOTP = HOTP(K, T), where T is an integer and represents the number of time steps between the initial counter time T0 and the current Unix time.
More specifically, T = (Current Unix time - T0) / X, where the default floor function is used in the computation.
For example, with T0 = 0 and Time Step X = 30, T = 1 if the current Unix time is 59 seconds, and T = 2 if the current Unix time is 60 seconds.
According to the description above, we need to obtain the time step X and the timestamp parameter T (usually in UTC timestamp format, measured in seconds). In general, the parameter T0 is 0, so subtraction calculation can be omitted.
Selon la description ci-dessus, nous devons obtenir le pas de temps X et le paramètre de l’horodatage T (généralement au format horodatage UTC, mesuré en secondes). En général, le paramètre T0 est de 0, donc le calcul de soustraction peut être omis.
根据上面的描述,我们需要获得时间步长 X 和时间戳参数 T (一般为 UTC 时间戳,单位为秒)。一般情况下,参数 T0 为 0,因此可以不执行减法计算。
1 2 3
var x = 30; // Time step in seconds var timeestamp = DateTime.UtcNow.Subtract(new DateTime(1970, 1, 1)).TotalSeconds; // Current UTC timestamp var t = (int)Math.Floor(unixTimestamp / x);
Step 2
Finally, by using the parameter T as the Counter parameter for HOTP, you can obtain the one-time password (OTP) for TOTP.
Enfin, en utilisant le paramètre T comme paramètre de « Counter » pour HOTP, vous pouvez obtenir le mot de passe à usage unique (OTP) pour TOTP.
最后,将参数 T 作为 HOTP 的 Counter 参数传入,就可以得到 TOTP 的一次性密码
1 2
var totp = new HOTP(SECRET, t, DIGIT); // This is pseudocode, please refer to the complete code example provided at the end of the article. var code = totp.Code(); // Also pseudocode...
Step 3
In this step, we will discuss the correctness after the implementation of the TOTP algorithm is completed… First of all, here is the complete code for the entire project.
À cette étape, nous allons discuter de la justesse après que l’implémentation de l’algorithme TOTP est achevée… Tout d’abord, voici le code complet pour l’ensemble du projet.
publicHOTP(byte[] secret, int counter, int digit) { Secret = secret; Digit = digit; var bytes = newbyte[8];
for (var i = 7; i >= 0; i--) { bytes[i] = (byte)(counter & 0xFF);
counter >>= 8; }
Counter = bytes; }
publicstringCode() { var hmac = new HMACSHA1(Secret); var hs = hmac.ComputeHash(Counter); var code = (DynamicTruncation(hs) % (int)Math.Pow(10, Digit)).ToString().PadLeft(Digit, '0');
return code; }
privateintDynamicTruncation(byte[] p) { var offset = p.Last() & 0x0F;
publicTOTP(byte[] secret, int timestep, int digit) { Secret = secret; Timestep = timestep; Digit = digit; }
publicstringCode() { var unixTimestamp = DateTime.UtcNow.Subtract(new DateTime(1970, 1, 1)).TotalSeconds; var t = (int)Math.Floor(unixTimestamp / Timestep); var hotp = new HOTP(Secret, t, Digit); var code = hotp.Code();
return code; } }
In the standard, Appendix B, there are also test cases similar to HOTP. However, please note that the Digit parameter in the test cases consists of 8 digits, not 6 digits.
Dans la norme, Annexe B, il existe également des cas de test similaires à HOTP. Cependant, veuillez noter que le paramètre Digit dans les cas de test est constitué de 8 chiffres, et non pas de 6 chiffres.
The test token shared secret uses the ASCII string value "12345678901234567890". With Time Step X = 30, and the Unix epoch as the initial value to count time steps, where T0 = 0, the TOTP algorithm will display the following values for specified modes and timestamps.
To test the correctness of this standard implementation, it is necessary to compute the same TOTP result based on the timestamps and keys provided in the test cases. Therefore, we need to make slight modifications and update the logic related to the T parameter of TOTP as follows:
Pour tester la justesse de cette mise en œuvre standard, il est nécessaire de calculer le même résultat TOTP en se basant sur les horodatages et les clés fournis dans les cas de test. Par conséquent, nous devons apporter de légères modifications et mettre à jour la logique liée au paramètre T de TOTP comme suit :
为了测试该标准实现的正确性,需要根据测试用例中提供的时间戳和密钥计算出同样的 TOTP 结果。因此我们需要稍作修改,将 TOTP 的 T 参数相关的逻辑代码修改成如下:
1 2 3 4 5
+-------------+--------------+------------------+----------+--------+ | Time (sec) | UTC Time | Value of T (hex) | TOTP | Mode | +-------------+--------------+------------------+----------+--------+ | 1234567890 | 2009-02-13 | 000000000273EF07 | 89005924 | SHA1 | +-------------+--------------+------------------+----------+--------+
1 2 3 4 5 6 7 8 9 10
publicstringCode() { var unixTimestamp = DateTime.UtcNow.Subtract(new DateTime(1970, 1, 1)).TotalSeconds; var testTimestamp = 1234567890; var t = (int)Math.Floor((double)testTimestamp / Timestep); var hotp = new HOTP(Secret, t, Digit); var code = hotp.Code();
return code; }
1 2 3 4 5 6 7 8 9
classProgram { publicstaticvoidMain() { var totp = new TOTP(Encoding.ASCII.GetBytes("12345678901234567890"), 30, 8);
Console.WriteLine(totp.Code()); } }
1 2 3 4 5
89005924
C:\Users\xyfbs\source\repos\ConsoleTotp\ConsoleTotp\bin\Debug\net7.0\ConsoleTotp.exe (process 45364) exited with code 0. To automatically close the console when debugging stops, enable Tools->Options->Debugging->Automatically close the console when debugging stops. Press any key to close this window . . .
Look, we are able to calculate the correct results given by the test cases in the standard.
Regardez, nous sommes capables de calculer les résultats corrects donnés par les cas de test dans la norme.
看,我们能计算出标准中的测试用例给的正确结果了
Appendix / 附录
Base32
In typical real-world usage, keys are often encoded using Base32. To obtain the correct results, developers usually need to decode the key using Base32 before proceeding. As a result, I will provide the implementation I’ve used for Base32 decoding in this article.
Dans des cas d’utilisation réels courants, les clés sont souvent encodées en utilisant le format Base32. Pour obtenir les résultats corrects, les développeurs doivent généralement décoder la clé en utilisant le décodage Base32 avant de continuer. Par conséquent, je vais fournir dans cet article l’implémentation que j’ai utilisée pour le décodage en Base32.
/* * Derived from https://github.com/google/google-authenticator-android/blob/master/AuthenticatorApp/src/main/java/com/google/android/apps/authenticator/Base32String.java * * Copyright (C) 2016 BravoTango86 * * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */
publicstaticbyte[] FromBase32String(string encoded) { if (encoded == null) thrownew ArgumentNullException(nameof(encoded));
// Remove whitespace and padding. Note: the padding is used as hint // to determine how many bits to decode from the last incomplete chunk // Also, canonicalize to all upper case encoded = encoded.Trim().TrimEnd('=').ToUpper(); if (encoded.Length == 0) returnnewbyte[0];
var outLength = encoded.Length * _shift / 8; var result = newbyte[outLength]; var buffer = 0; var next = 0; var bitsLeft = 0; var charValue = 0; foreach (var c in encoded) { charValue = CharToInt(c); if (charValue < 0) thrownew FormatException("Illegal character: `" + c + "`");
publicstaticstringToBase32String(byte[] data, int offset, int length, bool padOutput = false) { if (data == null) thrownew ArgumentNullException(nameof(data));
if (offset < 0) thrownew ArgumentOutOfRangeException(nameof(offset));
if (length < 0) thrownew ArgumentOutOfRangeException(nameof(length));
if ((offset + length) > data.Length) thrownew ArgumentOutOfRangeException();
if (length == 0) return"";
// SHIFT is the number of bits per output character, so the length of the // output is the length of the input multiplied by 8/SHIFT, rounded up. // The computation below will fail, so don't do it. if (length >= (1 << 28)) thrownew ArgumentOutOfRangeException(nameof(data));
var outputLength = (length * 8 + _shift - 1) / _shift; var result = new StringBuilder(outputLength);
var last = offset + length; int buffer = data[offset++]; var bitsLeft = 8; while (bitsLeft > 0 || offset < last) { if (bitsLeft < _shift) { if (offset < last) { buffer <<= 8; buffer |= (data[offset++] & 0xff); bitsLeft += 8; } else { int pad = _shift - bitsLeft; buffer <<= pad; bitsLeft += pad; } } int index = _mask & (buffer >> (bitsLeft - _shift)); bitsLeft -= _shift; result.Append(_digits[index]); } if (padOutput) { int padding = 8 - (result.Length % 8); if (padding > 0) result.Append('=', padding == 8 ? 0 : padding); } return result.ToString(); } }
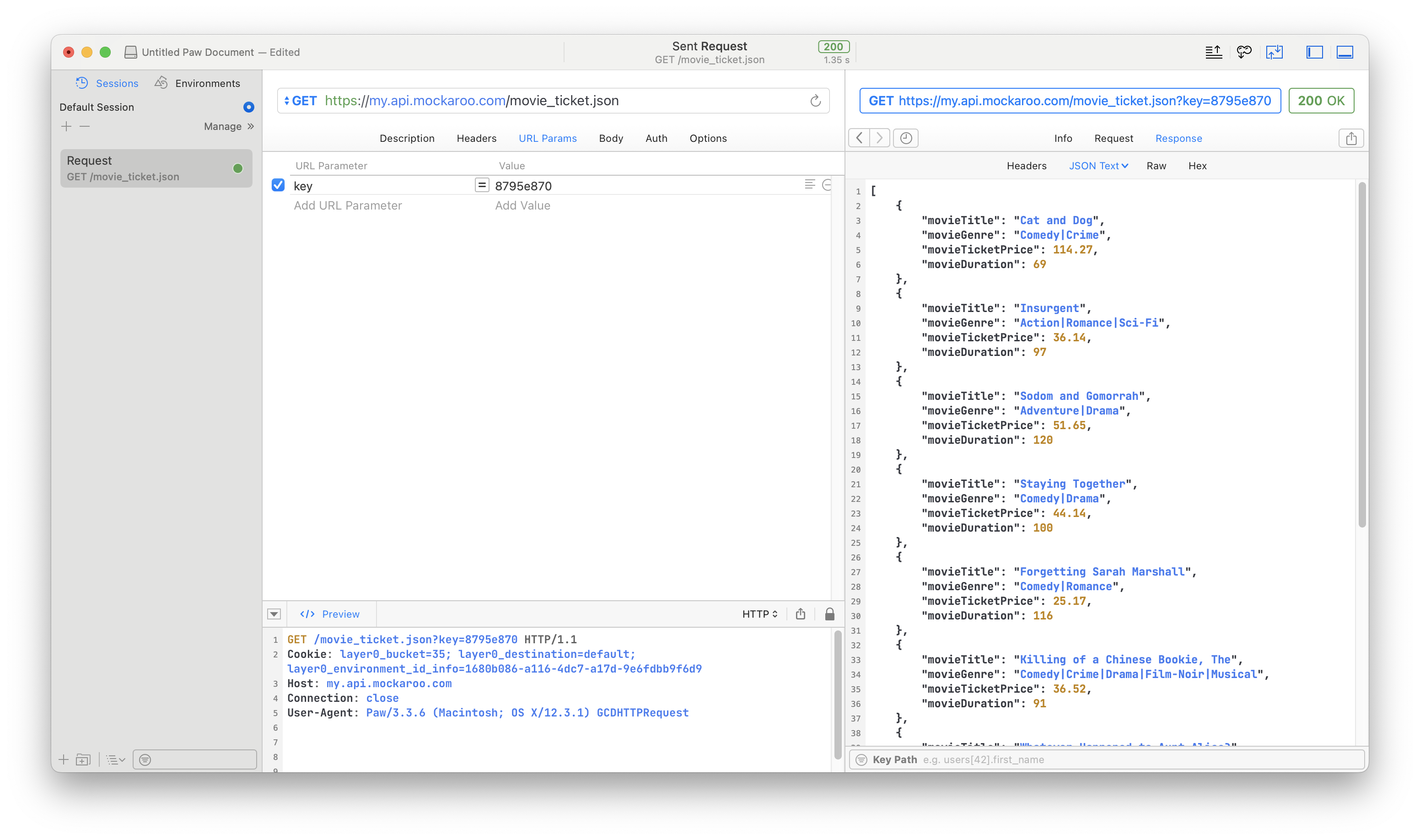
To test the usability of the TOTP code with real keys, I recommend using the TOTP testing page provided by Authentication Test as a test case. The key is typically I65VU7K5ZQL7WB4E (but please refer to the key provided on the website). The time step X parameter and the Digit parameter are usually set to common values of 30 and 6, respectively.
Pour tester l’efficacité du code TOTP avec des clés réelles, je recommande d’utiliser la page de test TOTP proposée par Authentication Test comme cas de test. La clé est généralement I65VU7K5ZQL7WB4E (mais veuillez vous référer à la clé fournie sur le site web). Le paramètre d’intervalle de temps X et le paramètre Digit sont généralement définis à des valeurs courantes de 30 et 6, respectivement.
为了测试 TOTP 代码在真实密钥情况下的可用性,我推荐 Authentication Test 的 TOTP 测试页面作为测试用例。密钥一般为 I65VU7K5ZQL7WB4E (但请还是根据网站提供的密钥为准)。时间步长 X 参数和 Digit 参数分别为常用的 30 和 6。
1 2 3 4 5 6 7 8 9
classProgram { publicstaticvoidMain() { var totp = new TOTP(Base32.FromBase32String("I65VU7K5ZQL7WB4E"), 30, 6);
Console.WriteLine(totp.Code()); // You will obtain a usable TOTP one-time password result. } }
Once you have the result, enter the TOTP password, click on “Login,” and observe whether you can successfully log in.
Après avoir obtenu le résultat, saisissez le mot de passe TOTP, cliquez sur “Se connecter” et observez si vous pouvez vous connecter avec succès.
/* Step 1: Generate an HMAC-SHA-1 value Let HS = HMAC-SHA-1(K,C) // HS is a 20-byte string Step 2: Generate a 4-byte string (Dynamic Truncation) Let Sbits = DT(HS) // DT, defined below, // returns a 31-bit string Step 3: Compute an HOTP value Let Snum = StToNum(Sbits) // Convert S to a number in 0...2^{31}-1 Return D = Snum mod 10^Digit // D is a number in the range 0...10^{Digit}-1 */
// Step 1: Generate an HMAC-SHA-1 value size_t counter_length = sizeof(this->counter); string hs = OtpTools::generate_hmacsha1(this->secret, this->counter, counter_length); string hs_raw_string = OtpTools::hex_to_string(hs); // Convert hex into a 20-byte string (int)
// Step 2: Generate a 4-byte string (Dynamic Truncation) // Step 3: Comput an HOTP value int dynamic_truncation = this->dynamic_truncation(hs_raw_string); int code = dynamic_truncation % static_cast<int>(pow(10, this->digit)); string code_str = OtpTools::pad_left(to_string(code), this->digit);
string Totp::gen_code() { /* o X represents the time step in seconds (default value X = 30 seconds) and is a system parameter. o T0 is the Unix time to start counting time steps (default value is 0, i.e., the Unix epoch) and is also a system parameter. Basically, we define TOTP as TOTP = HOTP(K, T) More specifically, T = (Current Unix time - T0) / X */
int utc = OtpTools::get_current_utc_timestamp(); int t = static_cast<int>(floor(utc / this->time_step)); Hotp hotp(this->secret, this->digit, t); string result = hotp.gen_code();
]]>In this article, I will provide a rough overview of the main process from implementing HOTP to TOTP. I won’t delve into the detailed explanations of each line of code; instead, the primary focus will be on extracting the implementation steps and highlighting some points I encountered during the deve朋友,漫展,生日https://moe.jimmy0w0.me/2023/07/12/comicon-and-my-bd/2023-07-12T03:55:31.000Z2024-06-05T12:06:42.464Z
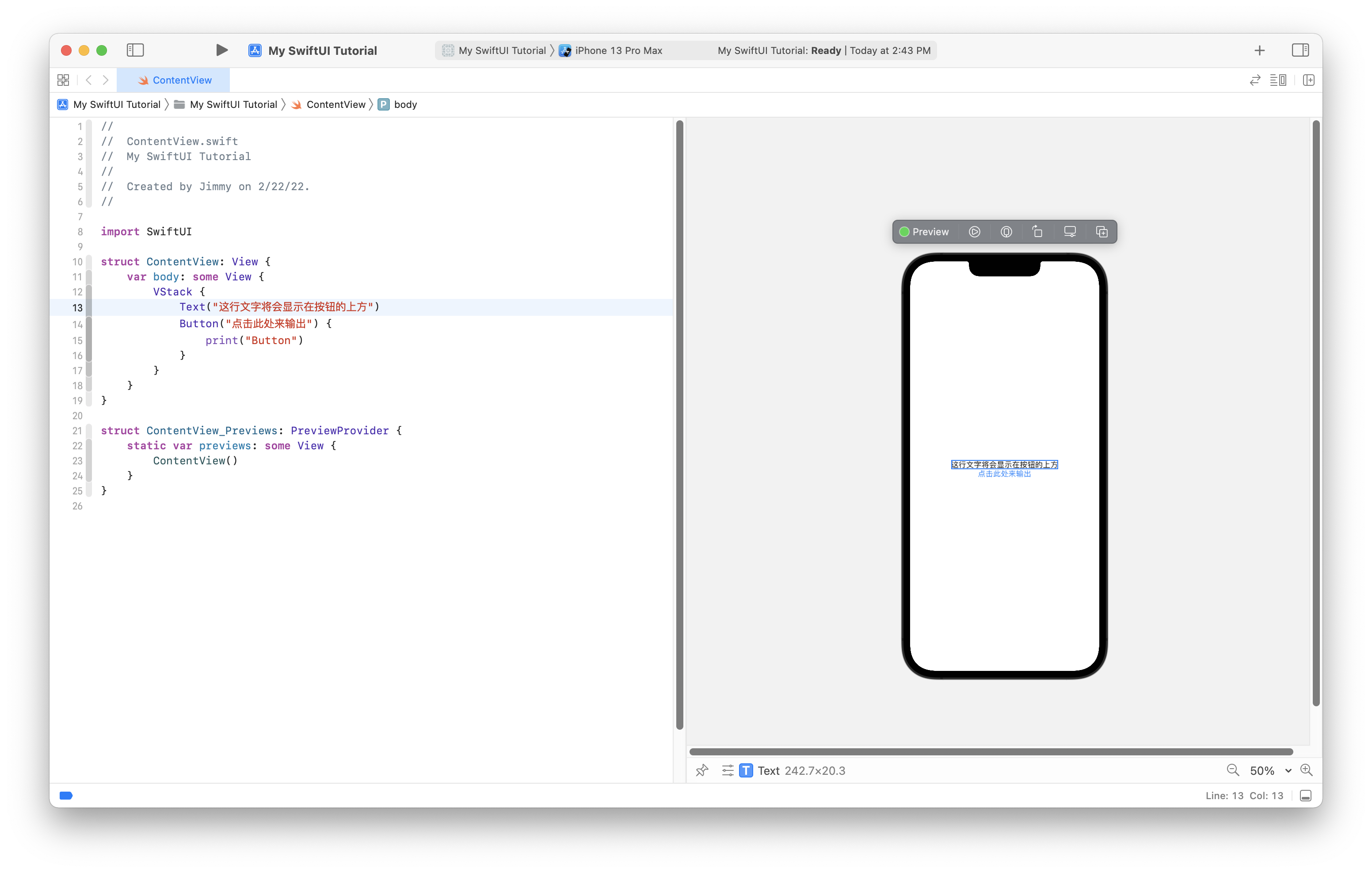
For developers who are too busy to read, I will briefly demonstrate how to develop a SwiftUI app using the MVVM pattern.
After creating a SwiftUI project in Xcode, you will usually get two Swift files, one with the same name as your project and the other one is generally called ContentView (may change over time, but currently it is still called ContentView).
Next, let’s create a View Model for ContentView.
Create a new Swift file and name it ContentViewViewModel, and remember to import SwiftUI at the top. Your code should look like this for now:
1
import SwiftUI
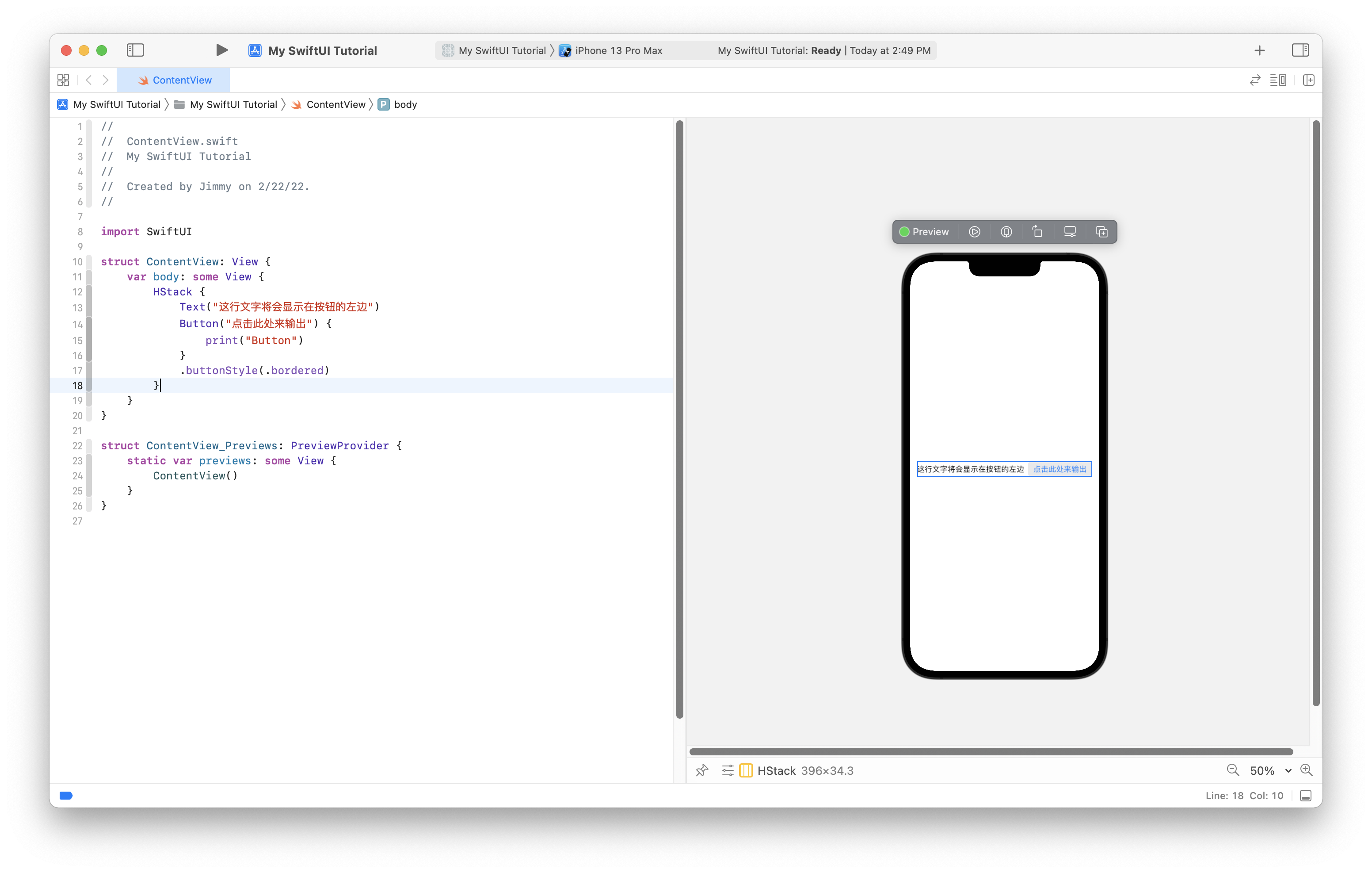
Now comes the highlight of the article. Because I want to create a View Model for ContentView instead of other Views, I can use a Swift feature called extension to extend ContentView, so that I can use what I am going to write in ContentView.
var body: someView { VStack { Text(viewModel.greetings) } } }
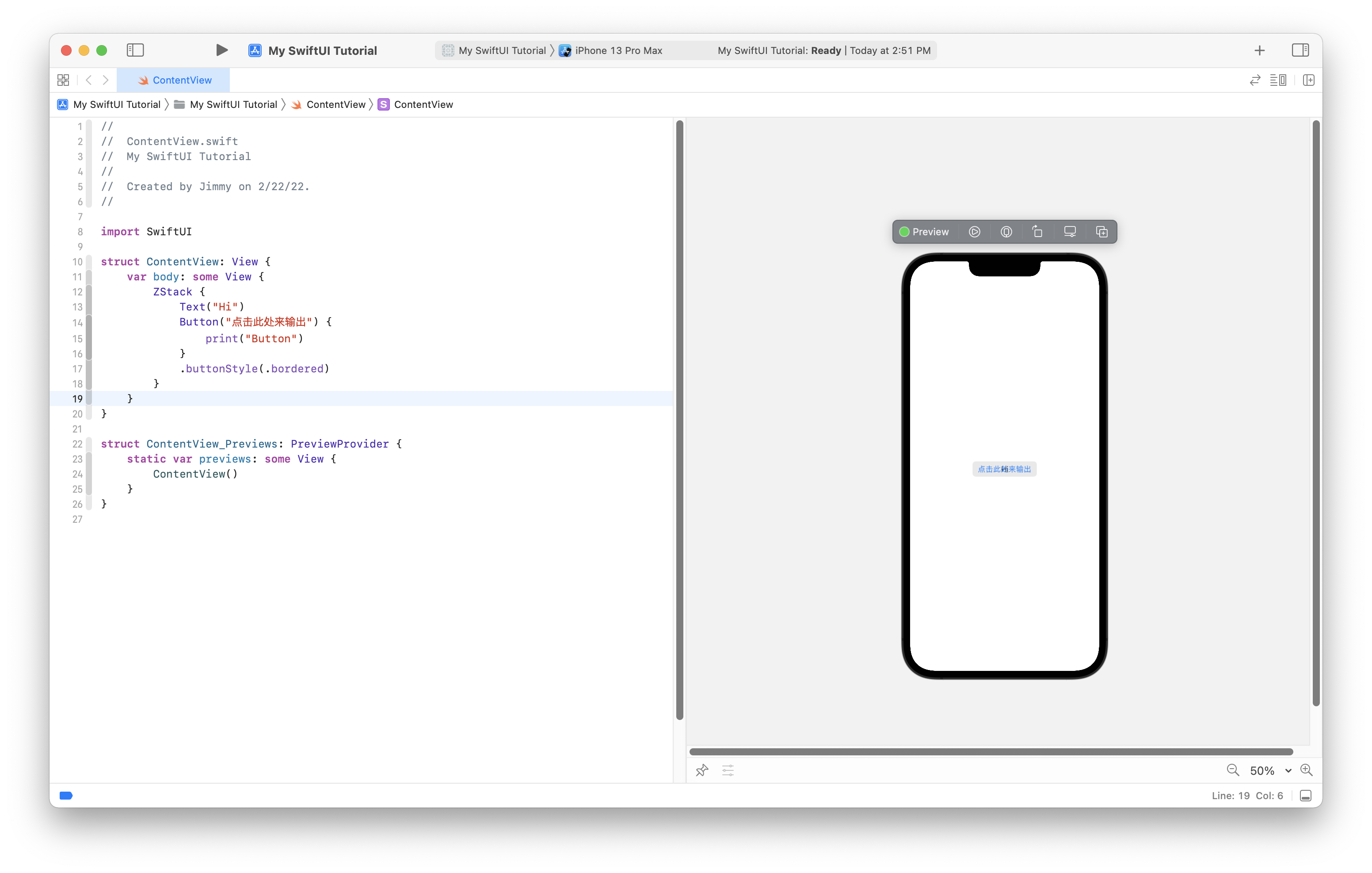
Great, we have already implemented the simplest MVVM. However, I am not going to end it here. I want to add the function of network requests to ContentViewViewModel to better meet the actual development needs.
[ { "userId":1, "id":1, "title":"sunt aut facere repellat provident occaecati excepturi optio reprehenderit", "body":"quia et suscipit\nsuscipit recusandae consequuntur expedita et cum\nreprehenderit molestiae ut ut quas totam\nnostrum rerum est autem sunt rem eveniet architecto" } ]
I will create the model in ContentViewViewModel, which makes it more convenient. In actual cases, it is recommended to create a separate file to build the model.
1 2 3 4
structPost: Decodable, Identifiable { let userId, id: Int let title, body: String }
Then, let’s write a function for requesting data in ContentViewViewModel, and call it in init() to achieve automatic request.
init() { Task { do { tryawait getPosts() } catch { print(error) // If there are other errors that do not cause a crash, print them here. } } }
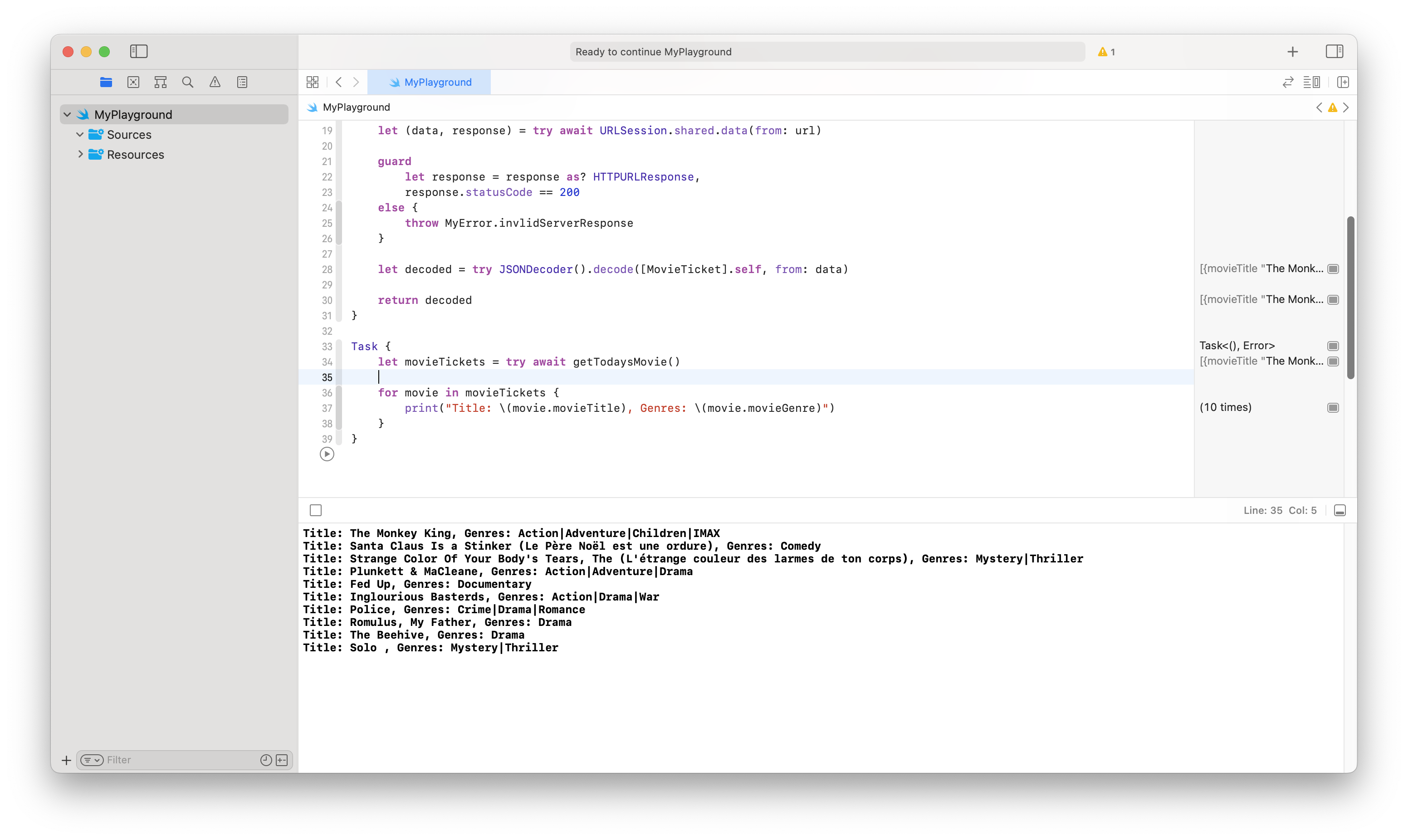
funcgetPosts() asyncthrows { guardlet url =URL(string: "https://jsonplaceholder.typicode.com/posts") else { fatalError() // If the URL is problematic, the app will crash here. NOT RECOMMENDED IN ACTUAL DEVELOPMENT. }
let (data, _) =tryawaitURLSession.shared.data(from: url) let posts =tryJSONDecoder().decode([Post].self, from: data)
self.posts = posts } } }
structPost: Decodable, Identifiable { let userId, id: Int let title, body: String }
var body: someView { NavigationView { if!viewModel.posts.isEmpty { List(viewModel.posts) { post in Text(post.title) } .navigationTitle("Posts") } } } }
Mission accomplished, now you already have some concepts about developing SwiftUI App using MVVM pattern.
]]>For developers who are too busy to read, I will briefly demonstrate how to develop a SwiftUI app using the MVVM pattern.
After creating a SwiftUI project in Xcode, you will usually get two Swift files, one with the same name as your project and the other one is generally called ContentView (may chaLaTeX Playgroundhttps://moe.jimmy0w0.me/2023/01/11/latex-playground/2023-01-11T23:01:10.000Z2024-06-05T12:06:42.468Z
]]>把官方文章翻译了: Valve Developer CommunityCounter-Strike: Global Offensive Game State Integrationhttps://moe.jimmy0w0.me/2022/07/04/csgo-game-state-integration/2022-07-04T19:11:50.000Z2024-06-05T12:06:42.464Z
Game State Integration 或 GSI 是一套可以允许任何第三方程序与游戏整合的一套系统。例如在实时直播的竞技比赛中自动控制舞台灯光和烟火系统,也可以让程序自动控制玩家的灯光或者任何其他的周边设施。通过 Game State Integration,开发者可以收集来自游戏内的实时游戏状态,将第三方的软件或者硬件设施与游戏绑定
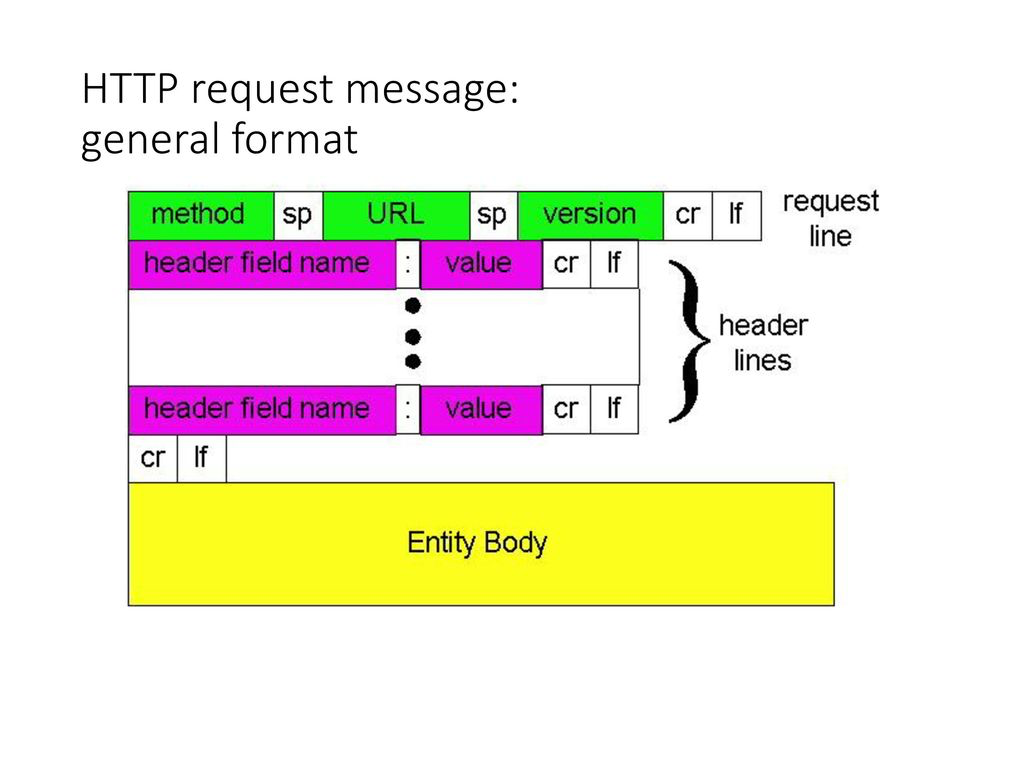
当 CS: GO 客户端需要向目标服务器发送状态时,CS: GO 将通过 HTTP 协议发起 POST 请求,Raw Body 的内容为标准的 JSON 格式
开始配置 GSI
如果需要在 CS: GO 中启动 GSI,需要向游戏的特定目录添加 .cfg 文件
目录路径位于: CS:GO 的根目录/csgo/cfg/
例如: /Volumes/Samsung T5/SteamLibrary/steamapps/common/Counter-Strike Global Offensive/csgo/cfg
"Console Sample v.1" { "uri" "http://127.0.0.1:3000" "timeout" "5.0" "buffer" "0.1" "throttle" "0.5" "heartbeat" "60.0" "auth" { "token" "CCWJu64ZV3JHDT8hZc" } "output" { "precision_time" "3" "precision_position" "1" "precision_vector" "3" } "data" { "provider" "1" // general info about client being listened to: game name, appid, client steamid, etc. "map" "1" // map, gamemode, and current match phase ('warmup', 'intermission', 'gameover', 'live') and current score "round" "1" // round phase ('freezetime', 'over', 'live'), bomb state ('planted', 'exploded', 'defused'), and round winner (if any) "player_id" "1" // player name, clan tag, observer slot (ie key to press to observe this player) and team "player_state" "1" // player state for this current round such as health, armor, kills this round, etc. "player_weapons" "1" // output equipped weapons. "player_match_stats" "1" // player stats this match such as kill, assists, score, deaths and MVPs } }
player_weapons - 所有武器目前状态(武器名,皮肤,类型,弹夹,弹夹支持的最大弹药数量,储备弹药用量,状态( active - 使用中,holstered - 未使用)
player_match_stats - 本局比赛数据(杀敌数,助攻数,死亡数,MVP,分数)
以上是官方提供的示例配置文件中会返回的数据
完整的 data 配置对象如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
"map_round_wins" "1" // history of round wins "map" "1" // mode, map, phase, team scores "player_id" "1" // steamid "player_match_stats" "1" // scoreboard info "player_state" "1" // armor, flashed, equip_value, health, etc. "player_weapons" "1" // list of player weapons and weapon state "provider" "1" // info about the game providing info "round" "1" // round phase and the winning team
// Below this line must be spectating or observing "allgrenades" "1" // grenade effecttime, lifetime, owner, position, type, velocity "allplayers_id" "1" // the steam id of each player "allplayers_match_stats" "1" // the scoreboard info for each player "allplayers_position" "1" // player_position but for each player "allplayers_state" "1" // the player_state for each player "allplayers_weapons" "1" // the player_weapons for each player "bomb" "1" // location of the bomb, who's carrying it, dropped or not "phase_countdowns" "1" // time remaining in tenths of a second, which phase "player_position" "1" // forward direction, position for currently spectated player
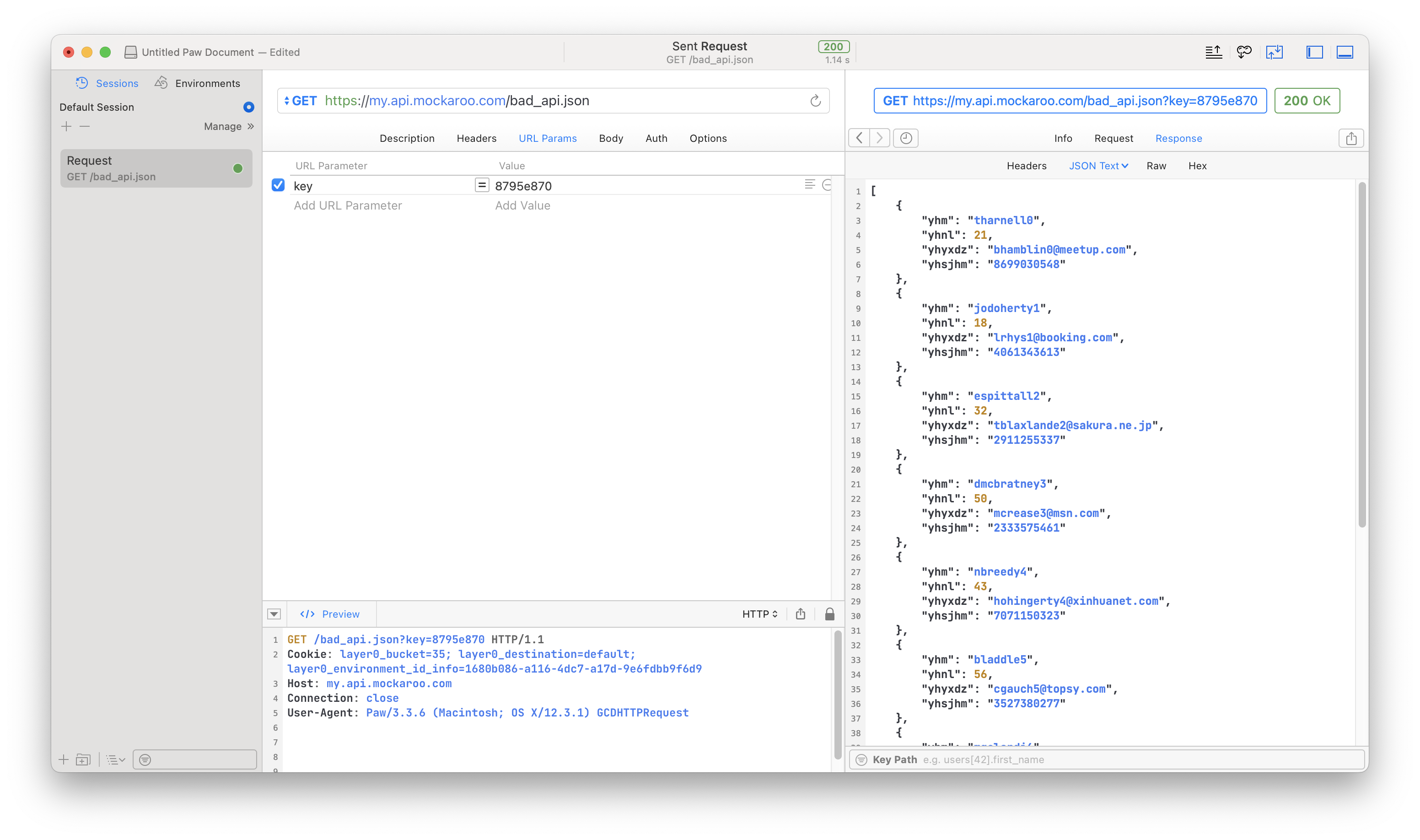
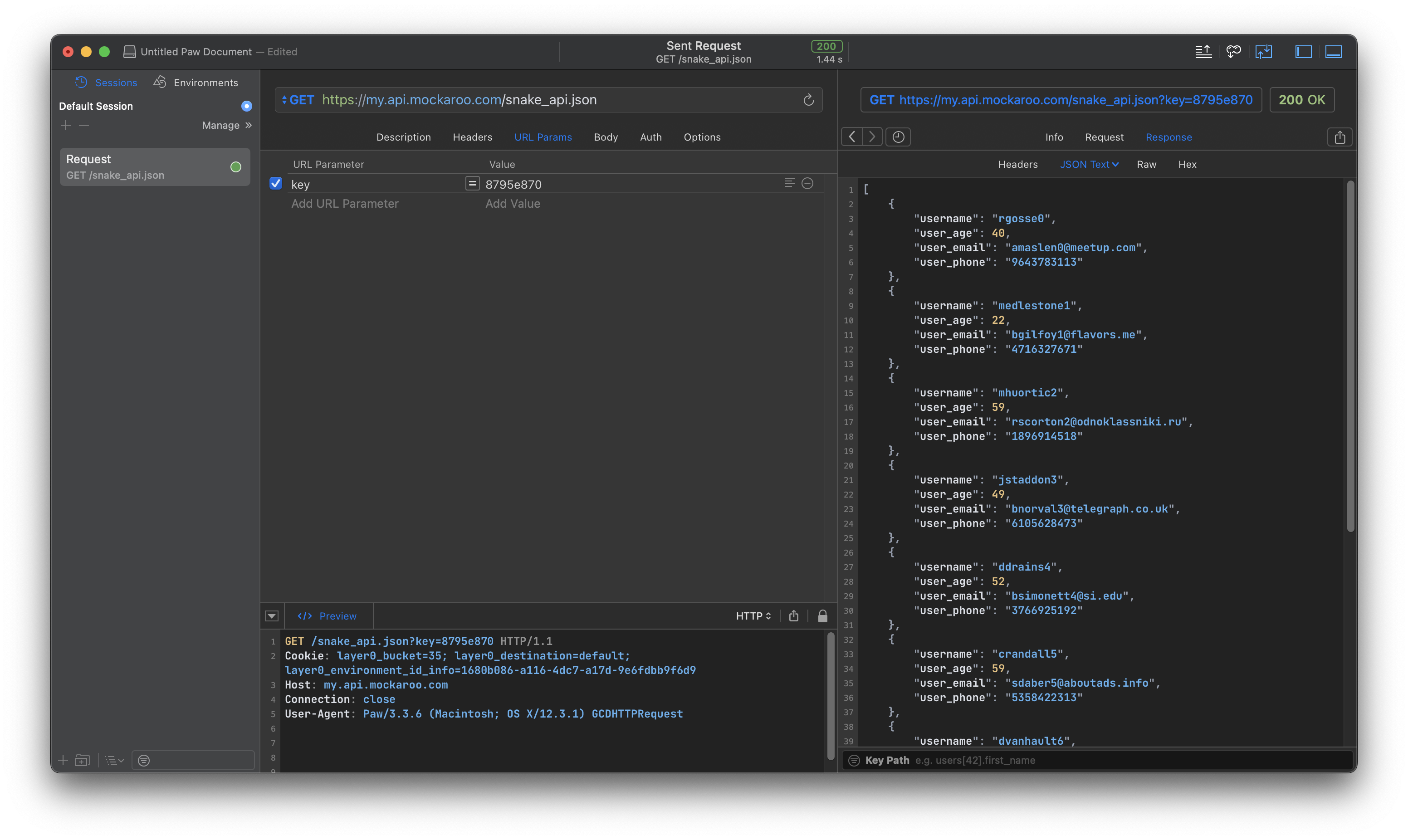
structUser: Codable { let username, userEmail, userPhone: String let userAge: Int privateenumCodingKeys: String, CodingKey { case username ="yhm" case userAge ="yhnl" case userEmail ="yhyxdz" case userPhone ="yhsjhm" } }
enumMyError: Error { case invlidUrl case invlidServerResponse }
structUser: Codable { let username, userEmail, userPhone: String let userAge: Int privateenumCodingKeys: String, CodingKey { case username ="yhm" case userAge ="yhnl" case userEmail ="yhyxdz" case userPhone ="yhsjhm" } }
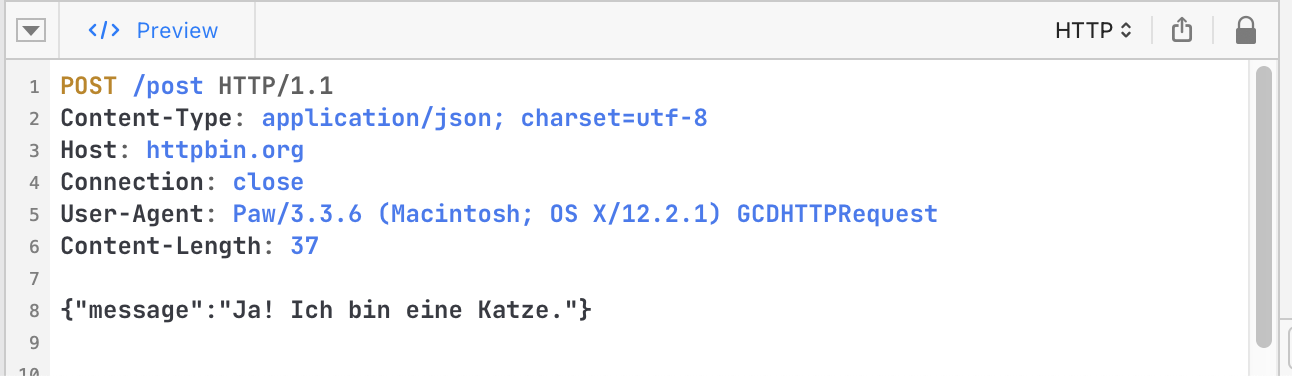
var httpMessage = "POST /post HTTP/1.1\r\nHost: httpbin.org\r\nContent-Type: application/json; charset=utf-8\r\nContent-Length: 38\r\n\r\n{\"message\": \"Ja! Ich bin eine Katze.\"}";
{ "args": {}, "data": "{\"message\": \"Ja! Ich bin eine Katze.\"}", "files": {}, "form": {}, "headers": { "Content-Length": "38", "Content-Type": "application/json; charset=utf-8", "Host": "httpbin.org", "X-Amzn-Trace-Id": "Root=1-623f17c3-2d7c46025329dd3f6cf0ea2f" }, "json": { "message": "Ja! Ich bin eine Katze." }, "origin": "203.198.218.99", "url": "http://httpbin.org/post" }
Httpbin 的服务器已经正确的理解了本次请求并且将 JSON 解析放入 json 对象中
最后放上整个程序的 C# 代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
var socket = new Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp); var httpMessage = "POST /post HTTP/1.1\r\nHost: httpbin.org\r\nContent-Type: application/json; charset=utf-8\r\nContent-Length: 38\r\n\r\n{\"message\": \"Ja! Ich bin eine Katze.\"}";
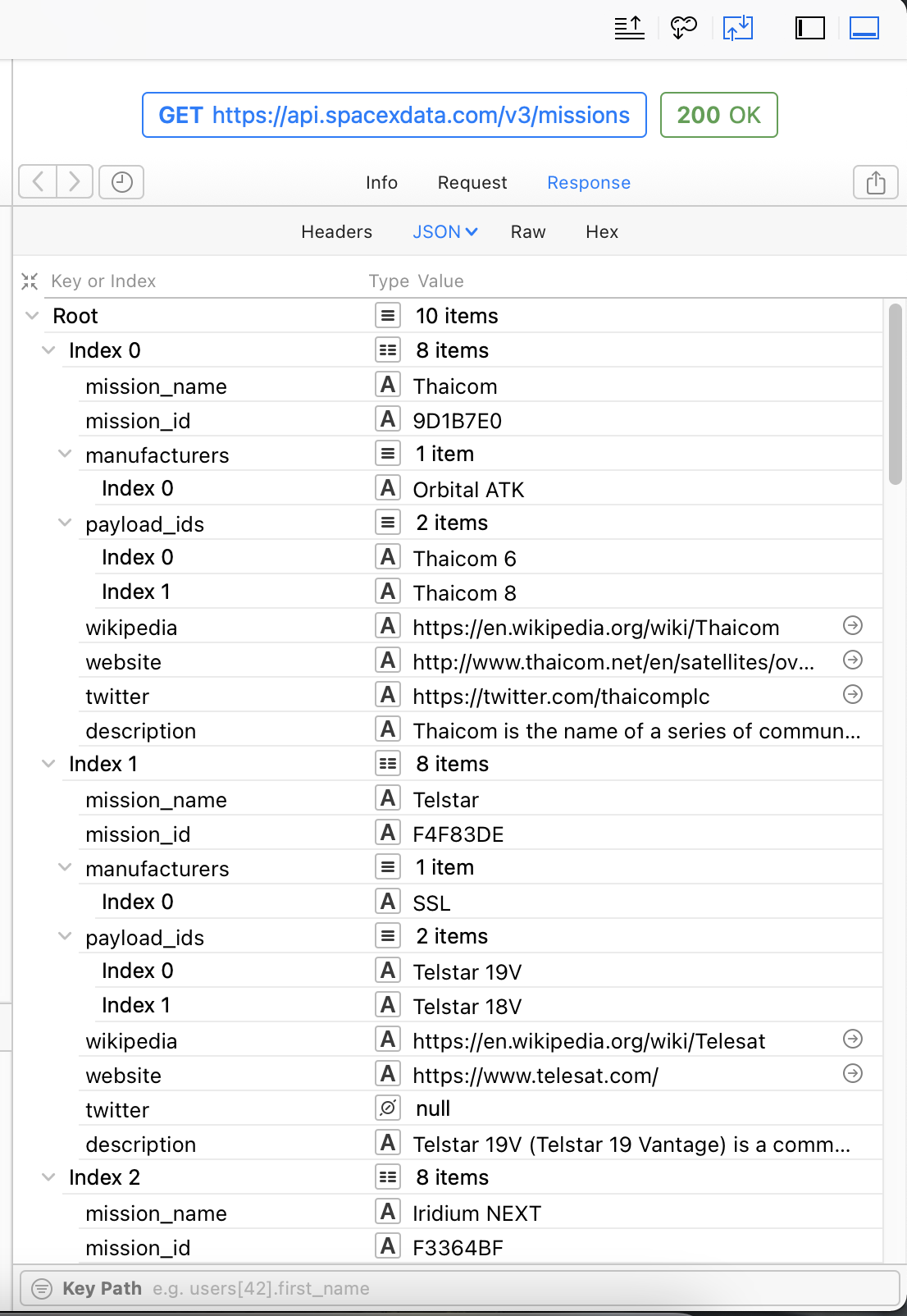
Swift 是一个静态类型的语言,在服务器返回 JSON 数据后反序列化前我们需要进行数据建模,我们先来分析一下 API 返回的 JSON 结构
Root 是我们 JSON 的起始花括号 {},并且 Root 的数据类型是一个 Array
因此返回的 Root 一定是 {[]}
所以,我们只需要着重建模数组内的单个数据模型即可
mission_name: string
mission_id: string
manufacturers: string[]
payload_ids: string[]
wikipedia: string
website: string
twitter: string
description: string
分析完毕后,我们在同一个 Playground 文件内建立一个新的结构体 struct
我们把这个 struct 叫做 SpacexMission
1 2 3 4 5 6 7 8 9 10
structSpacexMission { var mission_name: String var mission_id: String var manufacturers: [String] var payload_ids: [String] var wikipedia: String var website: String var twitter: String var description: String }
接下来我们使用 Swift 的 JSONDecoder 来对返回的数据反序列化
我们会利用 try! 来捕捉错误,但是我们暂时不想处理错误,如果出错就让程序先崩溃掉
1
let jsonData =try!JSONDecoder().decode(Decodable.Protocol, from: Data)
structSpacexMission: Codable { var mission_name: String var mission_id: String var manufacturers: [String] var payload_ids: [String] var wikipedia: String var website: String var twitter: String var description: String }
果不其然,这里有些 Twitter 的数据是 null,那我们需要在 struct 中让 Swift 知道这个 Twitter 是一个可选的
把我们的 Struct 改成这样
1 2 3 4 5 6 7 8 9 10
structSpacexMission: Codable { var mission_name: String var mission_id: String var manufacturers: [String] var payload_ids: [String] var wikipedia: String var website: String var twitter: String? var description: String }
然后再运行一次就不报错了
接下来我们就可以循环我们的数据了
1 2 3
for mission in jsonData { print(mission.mission_name) }
控制台就会成功输出
1 2 3 4 5 6 7 8 9 10
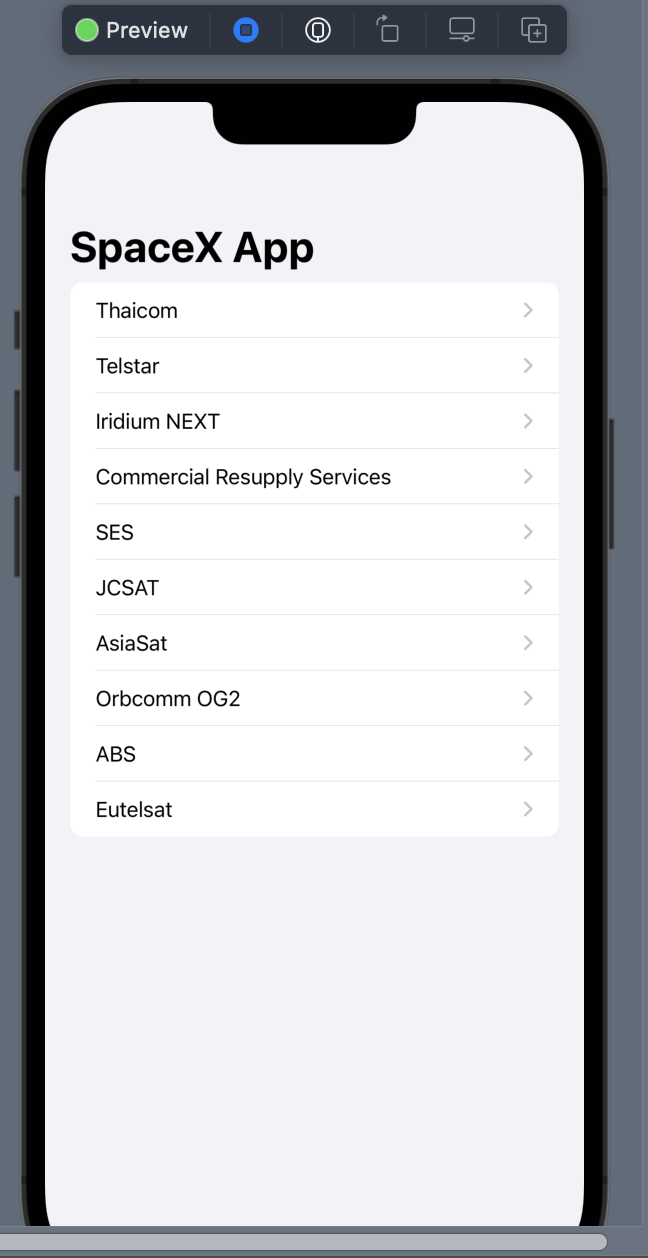
Thaicom Telstar Iridium NEXT Commercial Resupply Services SES JCSAT AsiaSat Orbcomm OG2 ABS Eutelsat
大功告成!
通过 URLRequest
在这里,我们会简单介绍一下 URLRequest
在 URLSession 中创建的 dataTask 默认都是 GET 方法
如果你需要执行其他的 HTTP 方法,往 Body 中加入数据,添加 Headers 等等操作,将会涉及到 URLRequest
// // SpaceXDataProvider.swift // SpaceXDemo // // Created by Jimmy on 2/16/22. //
import Foundation
structSpacexMission: Codable { var mission_name: String var mission_id: String var manufacturers: [String] var payload_ids: [String] var wikipedia: String var website: String var twitter: String? var description: String }
我们这里用到了 SwiftUI 的一个 List 组件,这里可能会报错,说 Initializer 'init(_:id:rowContent:)' requires that 'SpacexMission' conform to 'Hashable'
那我们到定义 SpacexMission 的地方让他遵循 Hashable 协议
1 2 3 4 5 6 7 8 9 10
structSpacexMission: Codable, Hashable { var mission_name: String var mission_id: String var manufacturers: [String] var payload_ids: [String] var wikipedia: String var website: String var twitter: String? var description: String }
存档网站这种事情方法有非常多种,有的存储下网页的源代码,有的用截屏,然后我选择用 PDF 来存储一个网页的内容
首先是 PDF 可以极大程度的还原网站的样貌,同时可以直接合并成单一文件,文件大小也可以接受;另一个是,PDF 同样具有可以交互的特性,比如你可以复制里面的文字,点击里面的超链接等等;最骚的是,你还可以通过一些工具 (比如 Windows 资源管理器自带的搜索功能) 来搜索 PDF 文件里面的内容,顺便还可以具有高亮文字,注记的特性
用户在 Telegram 中使用特定的命令 + 网页地址参数,就可以在服务端创建出 PDF 文件并且存档到一个地方
// Matches "/echo [whatever]" bot.onText(/\/echo (.+)/, (msg, match) => { // 'msg' is the received Message from Telegram // 'match' is the result of executing the regexp above on the text content // of the message
]]>Swift 不再单单用来开发 Apple 的应用程序,也可以开发服务端上的程序
安装依赖
1
sudo apt install clang libcurl3 libpython2.7 libpython2.7-dev
下载 Swift 5
1
wget https://swift.org/builds/swift-5.0-release/ubuntu1804/swift-5.0-RELEASE/swift-5.0-RELEASE-ubuntu18.04.tar.gz
解压
1
tar xzf swift-5.0-RELEASE-ubuntu18.04.tar.gz
移MacBook Air 升级到 macOS 11 Big Sur 后的一丢丢感受https://moe.jimmy0w0.me/2020/11/16/MacBook-Air-with-macOS-11-Big-Sur/2020-11-16T22:20:51.000Z2024-06-05T12:06:42.464Z
macOS Big Sur 最早在 WWDC 亮相的时候,看到的第一眼就肯定了一件事情
这绝对是 macOS 有史以来第三次大改
不过很不幸在当下并没有很习惯这次的大改,因为单单光看到全新的控制中心,小组件,新的图标…
就让我情不自禁想起了国产的各派 Linux 魔改 macOS 主题发行版
我甚至还害怕会不会有人在各种论坛下留言 「诶这不是什么什么 Linux 的 macOS 魔改主题吗」
不过在这几天的非深度体验了 Big Sur 之后,我对这种印象还是有所改观了不少
是的,UI 并没有那么糟
虽然这次全新的图标集在设计上简化了许多东西,再也没法继续体验到打开 Finder 中应用程序文件夹,然后把应用程序图标拉到最大找 Apple 那种变态级别的细节设计
不过确实也治好了我的 「Mac 审美疲劳」,配合新的提示框,提示音效,图标集,圆角菜单等等新的交互上的设计,确实让我感觉这台老 Mac 新鲜了不少
]]>macOS Big Sur 最早在 WWDC 亮相的时候,看到的第一眼就肯定了一件事情
这绝对是 macOS 有史以来第三次大改
不过很不幸在当下并没有很习惯这次的大改,因为单单光看到全新的控制中心,小组件,新的图标…
就让我情不自禁想起了国产的各派 Linux 魔改 macOS 主题发行版
我甚至还害怕会不会有人在各种论坛下留言 「诶这不是什么什么 Linux 的 macOS 魔改主题吗」
不过在这几天的非深度体验了 Big Sur 之后,我对这种印象还是有所改观了不少
是的,UI 并没有那么糟
虽然这次全新的图标集在设计上简化了许多东西,再也没法继续体验到打开 Finder 入门 Swift 第三章https://moe.jimmy0w0.me/2020/11/15/learn-swift-3/2020-11-15T21:50:38.000Z2024-06-05T12:06:42.468Z
]]>这是 Big sur 的新 UI 界面和一些功能
我是拿 Macbook Air 2014 中旬款来试水的,不过…
很卡!
至于主力机的 Macbook Pro 是否升级还是等大家排雷了再说吧 XD
终究我还是从小白鼠用户渐渐的到了养老等排雷的追求稳定的用户2020 Unity 中国线上技术大会https://moe.jimmy0w0.me/2020/11/13/unity-techweek-2020-online/2020-11-13T13:58:45.000Z2024-06-05T12:06:42.472Z
Tokyo (/ˈtoʊkioʊ/ TOH-kee-oh, /-kjoʊ/ -kyoh; Japanese: 東京, Tōkyō [toːkʲoː] (About this soundlisten)), officially Tokyo Metropolis (東京都, Tōkyō-to), is the capital and most populous prefecture of Japan. Located at the head of Tokyo Bay, the prefecture forms part of the Kantō region on the central Pacific coast of Japan’s main island of Honshu. Tokyo is the political and economic center of the country, as well as the seat of the Emperor of Japan and the national government. In 2019, the prefecture had an estimated population of 13,929,280. The Greater Tokyo Area is the most populous metropolitan area in the world, with more than 37.393 million residents as of 2020.
Originally a fishing village named Edo, the city became a prominent political center in 1603, when it became the seat of the Tokugawa shogunate. By the mid-18th century, Edo was one of the most populous cities in the world, with a population numbering more than one million. Following the end of the shogunate in 1868, the imperial capital in Kyoto was moved to the city, which was renamed Tokyo (literally “eastern capital”). Tokyo was devastated by the 1923 Great Kantō earthquake, and again by Allied bombing raids during World War II. Beginning in the 1950s, the city underwent rapid reconstruction and expansion, going on to lead Japan’s post-war economic recovery. Since 1943, the Tokyo Metropolitan Government has administered the prefecture’s 23 special wards (formerly Tokyo City), various bed towns in the western area, and two outlying island chains.
Tokyo is the largest urban economy in the world by gross domestic product, and is categorized as an Alpha+ city by the Globalization and World Cities Research Network. Part of an industrial region that includes the cities of Yokohama, Kawasaki, and Chiba, Tokyo is Japan’s leading center of business and finance. In 2019, it hosted 36 of the Fortune Global 500 companies. In 2020, it ranked fourth on the Global Financial Centres Index, behind New York City, London, and Shanghai.
The city has hosted multiple international events, including the 1964 Summer Olympics and three G7 Summits (1979, 1986, and 1993); it will also host the 2020 Summer Olympics, which were postponed to 2021 due to the COVID-19 pandemic. Tokyo is an international center of research and development and is represented by several major universities, notably the University of Tokyo. Tokyo Station is the central hub for Japan’s Shinkansen bullet train system, and the city is served by an extensive network of rail and subways. Notable districts of Tokyo include Chiyoda (the site of the Imperial Palace), Shinjuku (the city’s administrative center), and Shibuya (a commercial, cultural and business hub).
Chernobyl disaster - From EN Wikipedia
The Chernobyl disaster was caused by a nuclear accident that occurred on Saturday 26 April 1986, at the No. 4 reactor in the Chernobyl Nuclear Power Plant, near the city of Pripyat in the north of the Ukrainian SSR. It is considered the worst nuclear disaster in history and was caused by one of only two nuclear energy accidents rated at seven—the maximum severity—on the International Nuclear Event Scale, the other being the 2011 Fukushima Daiichi nuclear disaster in Japan.
The accident started during a safety test on an RBMK-type nuclear reactor, which was commonly used throughout the Soviet Union. The test was a simulation of an electrical power outage to aid the development of a safety procedure for maintaining reactor cooling water circulation until the back-up electrical generators could provide power. This gap was about one minute and had been identified as a potential safety problem that could cause the nuclear reactor core to overheat. It was hoped to prove that the residual rotational energy in a turbine generator could provide enough power to cover the gap. Three such tests had been conducted since 1982, but they had failed to provide a solution. On this fourth attempt, an unexpected 10-hour delay meant that an unprepared operating shift was on duty.
During the planned decrease of reactor power in preparation for the electrical test, the power unexpectedly dropped to a near-zero level. The operators were able to only partially restore the specified test power, which put the reactor in a potentially unstable condition. This risk was not made evident in the operating instructions, so the operators proceeded with the electrical test. Upon test completion, the operators triggered a reactor shutdown, but a combination of unstable conditions and reactor design flaws caused an uncontrolled nuclear chain reaction instead.
A large amount of energy was suddenly released, vaporising superheated cooling water and rupturing the reactor core in a highly destructive steam explosion. This was immediately followed by an open-air reactor core fire that released considerable airborne radioactive contamination for about nine days that precipitated onto parts of the USSR and western Europe, especially Belarus, 16km away, where around 70% landed, before being finally contained on 4 May 1986. The fire gradually released about the same amount of contamination as the initial explosion. As a result of rising ambient radiation levels off-site, a 10-kilometre (6.2 mi) radius exclusion zone was created 36 hours after the accident. About 49,000 people were evacuated from the area, primarily from Pripyat. The exclusion zone was later increased to 30 kilometres (19 mi) radius when a further 68,000 people were evacuated from the wider area.
The reactor explosion killed two of the reactor operating staff. In the emergency response that followed, 134 station staff and firemen were hospitalized with acute radiation syndrome due to absorbing high doses of ionizing radiation. Of these 134 people, 28 died in the days to months afterward and approximately 14 suspected radiation-induced cancer deaths followed within the next 10 years.
Among the wider population, an excess of 15 childhood thyroid cancer deaths were documented as of 2011. The United Nations Scientific Committee on the Effects of Atomic Radiation (UNSCEAR) has, at multiple times, reviewed all the published research on the incident and found that at present, fewer than 100 documented deaths are likely to be attributable to increased exposure to radiation. Determining the total eventual number of exposure related deaths is uncertain based on the linear no-threshold model, a contested statistical model, which has also been used in estimates of low level radon and air pollution exposure. Model predictions with the greatest confidence values of the eventual total death toll in the decades ahead from Chernobyl releases vary, from 4,000 fatalities when solely assessing the three most contaminated former Soviet states, to about 9,000 to 16,000 fatalities when assessing the total continent of Europe.
To reduce the spread of radioactive contamination from the wreckage and protect it from weathering, the protective Chernobyl Nuclear Power Plant sarcophagus was built by December 1986. It also provided radiological protection for the crews of the undamaged reactors at the site, which continued operating. Due to the continued deterioration of the sarcophagus, it was further enclosed in 2017 by the Chernobyl New Safe Confinement, a larger enclosure that allows the removal of both the sarcophagus and the reactor debris, while containing the radioactive hazard. Nuclear clean-up is scheduled for completion in 2065. The Chernobyl disaster is considered the worst nuclear power plant accident in history, both in terms of cost and casualties. The initial emergency response, together with later decontamination of the environment, ultimately involved more than 500,000 personnel and cost an estimated 18 billion Soviet rubles—roughly US$68 billion in 2019, adjusted for inflation. The accident resulted in safety upgrades on all remaining Soviet-designed RBMK reactors, of which 10 continue to be operational as of 2019.
]]>这是一篇翻译测试用文章
Tokyo - From EN Wikipedia
Tokyo (/ˈtoʊkioʊ/ TOH-kee-oh, /-kjoʊ/ -kyoh; Japanese: 東京, Tōkyō [toːkʲoː] (About this soundlisten)), officially Tokyo Metropolis (東京都, Tōkyō-to), is the capital and most populous prefecture of Japan. Located at the head of Tokyo Bay, the prefecture forms partApple Event 2020/11/10https://moe.jimmy0w0.me/2020/11/12/Apple-Event-2020-11-10/2020-11-12T22:44:38.000Z2024-06-05T12:06:42.464Z
Apple 在中国时间 2020 年 11 月 11 日的凌晨两点召开了今年第四次在线大会,也将会是 Apple 在今年最后一场大会
A Alt CtrlW Command⌘Q 这个插件对于某些教程文章还挺管用的]]>没错,又安装了一个新的 Hexo Tag Plugin
这次的插件是用来显示键盘键位的: hexo-tag-kbd
效果如下
A
Alt
CtrlW
Command⌘Q
这个插件对于某些教程文章还挺管用的RESTful API 输出文章摘要https://moe.jimmy0w0.me/2020/10/29/output-excerpt/2020-10-29T08:59:08.000Z2024-06-05T12:06:42.472Z
安装了一个新的插件 hexo-auto-excerpt
可以让文章自动输出摘要到 HTML 的 HEAD 标签中,并且可以被 RESTful API 的插件抓到
]]>安装了一个新的插件 hexo-auto-excerpt
可以让文章自动输出摘要到 HTML 的 HEAD 标签中,并且可以被 RESTful API 的插件抓到jsDelivr 清除缓存https://moe.jimmy0w0.me/2020/10/28/jsdelivr-purge-cache/2020-10-28T20:10:57.000Z2024-06-05T12:06:42.468Z
]]>iOS 13.6 出来了,以下是已知或者可以感知到的更新内容
Apple Car Keys
Apple Car Keys 是这次更新的最大亮点,也是于 WWDC 2020 新发布的功能
目前将会支持 BMW 于 2020 年 7 月 1 日之后的新车型,其他品牌将会陆续跟进
健康
新的健康 App 中加入了 「症状」 选项,可以添加和记录症状
Face ID
当原深感摄像头检测到面部遮挡 (戴口罩) 的时候,会立即终止 Face ID 的识别过程
改成使用密码或者开发者自定的身份验证方式App Review 和 Feature Review 系列https://moe.jimmy0w0.me/2020/06/20/app-review-and-feature-review/2020-06-20T12:59:13.000Z2024-06-05T12:06:42.464Z
]]>是的,戴着口罩解锁 iPhone Xr
因为 Face ID 具有学习能力,因此戴着口罩输入密码,多了之后…
它就真的可以戴着口罩识别了
虽然摘口罩识别之后,过一段时间戴口罩又不能识别了,不过…啊算是一个方法吧从 iPhone SE 到 iPhone Xrhttps://moe.jimmy0w0.me/2020/05/22/iPhoneSE-to-iPhoneXR/2020-05-22T23:52:31.000Z2024-06-05T12:06:42.468Z
]]>这篇文章已经被加密从 iPhone SE 到 iPhone Xrhttps://moe.jimmy0w0.me/2020/05/22/se-to-xr/2020-05-22T23:02:54.000Z2024-06-05T12:06:42.472Z
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
]]>Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
Quick Start
Create a new post
1
$ hexo new "My New Post"
More info: Writing
Run server
1
$ hexo s别了电脑?华为突然公布一个黑科技?https://moe.jimmy0w0.me/2019/10/08/no-huawei-cloud-computer/2019-10-08T20:27:54.000Z2024-06-05T12:06:42.472Z